Реализация таблиц символов в различных конструкциях компиляторов - весьма слабо освещенный вопрос как в литературе, так и в документации по конкретным системам. Сам термин "таблица символов" практически не соответствует существу возникающих при компиляции структур данных и сохраняется в терминологии исключительно в силу сложившейся исторической традиции.
Мы также используем этот устаревший термин, но понимаем под этим совокупность структур данных, дисциплину их обработки и логические связи между ними, возникающие в процессе компиляции с языков высокого уровня.
Новые подходы к проблеме видимости, выдвинутые в современных языках, таких как Модула-2 и Ада, предъявляют нетрадиционные требования к конструированию этих таблиц. Целью данной работы является детализация этих требований и рассмотрение путей их конкретной реализации.
Существуют три основных отличия трактовки видимости в языках Модула-2 и Ада, в отличие от традиционных языков (Алгол-68, Паскаль, и т.п.):
- Модульная структура единиц компиляции.
- Требование к полному и точному определению интерфейса между раздельно скомпилированными модулями и, как следствие, необходимость сохранения информации о "таблицах символов" на длительное время с использованием этой информации для полного статического контроля. Возникает также задача поддержания хронологического порядка в сложноустроенном графе зависимости единиц компиляции ("таблиц символов").
- Возможность совмещения имен. Если несколько объектов названы одним именем, впоследствии поиск нужного объекта может быть решен с использованием контекстных ограничений и информации о каждом из соименных объектов.
При конструировании конкретной структуры таблицы символов (и ее внешнего представления), удовлетворяющей указанным требованиям, основным аспектом, на котором мы старались сконцентрировать внимание, является максимально возможное отвлечение от свойств конкретного представления объектов и наиболее универсальная реализация абстрактных типов данных, представительно описывающих работу с конструируемыми таблицами символов.
Перевод идентификаторов во внутреннюю форму и наоборот - действие тривиальное, легко решаемое с помощью любого из известных методов. Поэтому считаем, что имеются два отображения:
StrId : String -> Id
IdStr : Id -> String
которые осуществляют необходимые переводы.
При этом внутренняя структура абстрактного типа Id остается для всех использующих его модулей скрытой:
DEFINITION MODULE Idents:
EXPORT QUALIFIED Id, StrId, IdStr;
TYPE Id; (*Скрытый*)
PROCEDURE StrId (S: ARRAY OF CHAR): Id;
PROCEDURE IdStr (Ident: Id; VAR S: ARRAY OF Char);
END Idents.
Кроме того, существует множество объектов, представляемых типом Obj, каждый из которых обладает некоторым "видом" (типа Modes) и неким набором атрибутов, причем можно считать, что тип самих атрибутов универсален, т.е. не фиксируется конкретной реализацией. Таким образом, имеем следующие (конструируемые) отображения:
GenObj : Modes -> Obj - создает новый объект указанного вида,
mode? : Obj -> Mode - позволяет определить вид объекта,
SetAtr : Obj х Atr х Univ -> - устанавливает атрибут,
GetAtr : Obj х Atr -> Univ - определяет значения атрибута.
Отображение GetAtr не является просто обращением отображения SetAtr, часть его значений может (и должно) быть вычислено на базе значений других установленных атрибутов. Такие вычисления определяются семантикой конкретного языка и изменяются в зависимости от реализации. Итак, мы получили следующую структуру:
DEFINITION MODULE Obje;
EXPORT QUALIFIED Obj, Modes, Atr, SAT, GAT, Mode?, GenObj;
TYPE Modes = (invalid, variable, constant, proced, modul, ...);
(* Множество конкретных видов зависит от языка и выбирается по усмотрению реализатора. Вид invalid вводится для подавления наведенных сообщений об ошибках, для него допустима установка и опрашивание любых атрибутов. *)
TYPE Atr = (objsize, level, host, offset, objtype, arrinx, arrelelem, fieldlist, ...);
(* Множество атрибутов выбирается из соображения упрощения работы с объектом. Наши рекомендации при этом можно сформулировать так: старайтесь минимизировать число устанавливаемых атрибутов (т.е. атрибутов, значение которых необходимо установить для полного определения информации об объекте) и максимизировать число "вычисляемых" атрибутов, сконцентрировав тем самым все функциональные зависимости свойств объекта в одном месте и облегчив их верификацию и изменение. *)
TYPE Obj;
(* "Скрытый" тип, представляющий множество различных объектов. *)
PROCEDURE GenObj(m: Modes): Obj;
(* Порождает новый объект с множеством неопределенных атрибутов. Вид объекта после его порождения остается постоянным. *)
PROCEDURE Mode? (Ob: Obj): Modes;
(* Позволяет определить вид объекта. *)
PROCEDURE SAT(Ob: Obj; a: Atr; val: word);
(* Присваивает атрибуту указанное значение. При этом проверяется допустимость установки данного атрибута (в соответствии с видом объекта) и, возможно, вычисляются (модифицируются) некоторые другие атрибуты. Так, например, при добавлении поля к типу записи может измениться размер этого типа. *)
PROCEDURE GAT(Ob: Obj; a: Atr): word;
(* Позволяет узнать значение атрибута. Атрибут может быть ранее установленным, ранее вычисленным или вычисляемым в момент опрашивания. Рекомендуется проверять допустимость опроса данного атрибута в соответствии с видом указанного объекта. *)
END Objs.
Последней и наиболее важной структурой при конструировании таблицы символов является отображение видимости. Некоторые из порожденных в ходе компиляции объектов имеют имена, причем одному и тому же имени может соответствовать множество объектов:
Visible: Id х Obj x Obj - > - объявляет первый объект видимым под указанным именем, задаваемом в контексте вторым объектом;
Select: P(Obj) х GAT x Mode? -> Obj - используя отображения Mode?, GAT, и, возможно, дополнительную информацию о контексте, выбирают из указанного множества объектов единственный допустимый.
Поскольку представление некоторого подмножества множества Obj технически является достаточно сложной задачей, а единственная цель порождения такого подмножества - обработка (последовательная!) его операцией Select, авторами был найден элегантный подход к реализации необходимого набора отображений:
DEFINITION MODULE Visibility;
FROM Idents IMPORT Id;
FROM Objs IMPORT Obj;
EXPORT QUALIFIED MakeVisible, VisibleIterator, SelectProc;
TYPE SelectProc = PROCEDURE (Obj) : BOOLEAN;
PROCEDURE MakeVisible (i: Id; Ob: Obj; HostBlok: Obj);
(* Делает объект Ob видимым в контексте блока HostBlock под именем i. Если при этом возникает неоднородность именования, сообщает об ошибке и изменяет вид объекта Ob на Invalid (это единственный случай изменения вида объекта) с целью подавления повторных сообщений об ошибке. *)
PROCEDURE VisibleIterator(i: Id; HostBlock: Obj;
Select: SelectProc) : Obj;
(* Вызывает процедуру Select для всех объектов, видимых под именем i в контексте, задаваемом HostBlock , в случае если Select находит подходящий объект, итерация завершается возвращением логического результата из процедуры Select и выбранный объект возвращается процедурой VisibleIterator. В этом смысле VisibleIterator является простой функциональной композицией отображений Visible и Select, но именно результат работы такой композиции и представляет конкретный интерес для процесса идентификации объектов.
При таком итеративном просмотре множества видимых объектов могут достаточно легко и естественно решаться не только задачи, связанные с модульной структурой исходного текста, но и задачи совмещения имен. При этом структура модуля Visibility остается независимой (!!) от конкретных правил видимости языка программирования. *)
(* Замечание: Такие важные операции, как Export и Import, легко выражаются в терминах описываемых отображений, поэтому их спецификация в данном модуле не обязательна (так как они могут быть зависимыми от правил видимости конкретного языка). *)
END Visibility.
Многочисленные эксперименты с внешним представлением таблиц символов показали, что наиболее удобным для хранения и последующей работы является линейное представление графа в виде лексической свертки исходного текста с удаленными избыточными символами. При хранении таблиц символов в виде перемещаемого внутреннего представления возникают серьезные сложности при решении задач слияния таких таблиц и "перевешивания" ссылок из одной таблицы в другую. Последняя проблема возникает в случае повторного появления модуля в качестве косвенного кандидата на импорт в тот момент, когда другой модуль уже имеет ссылки на объекты из него (см. рисунок).
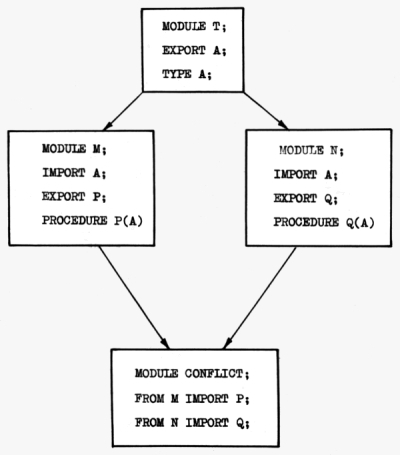
В момент импорта Q возникает "косвенная" ссылка на модуль T, таблица которого уже введена такой же "косвенной" ссылкой из объекта P.